本記事の概要
Vitisビジョンライブラリでテストベンチ関数を使った高位合成の方法と結果を紹介。
用例のcustomconvに含まれるFilter2D_accelを例にラプラシアンフィルタの高位合成と実装をめざす。本記事では高位合成を実行し、合成されたIPの構成を整理する。
Xilinxの統合ソフトウェア開発環境では、Vitisビジョンライブラリ(以下、ビジョンライブラリ)をインクルードすることによって、画像処理機能を高速化(アクセラレーション)することが可能です。例えば、OpenCVのフィルタ処理などを、FPGAに実装可能なロジックへと高位合成することができます。
本サイトでは実際にVitisビジョンライブラリのFilter2D_accel関数を例に、ラプラシアンフィルタを行う画像処理IPのCシミュレーション、高位合成、C/RTL協調シミュレーション、そして実装を進めていこうと思います。
前回の記事では、テストベンチでのCシミュレーションの方法を紹介しました。

本記事では、Cシミュレーションで動作確認ができたFilter2D_accel関数を高位合成したいと思います。
- Vitisビジョンライブラリを初めて扱う
- ビジョンライブラリの高位合成の方法と結果(リソース数やレイテンシー)を知りたい
高位合成
では、さっそく高位合成を行いましょう。
合成後のIPのイメージ
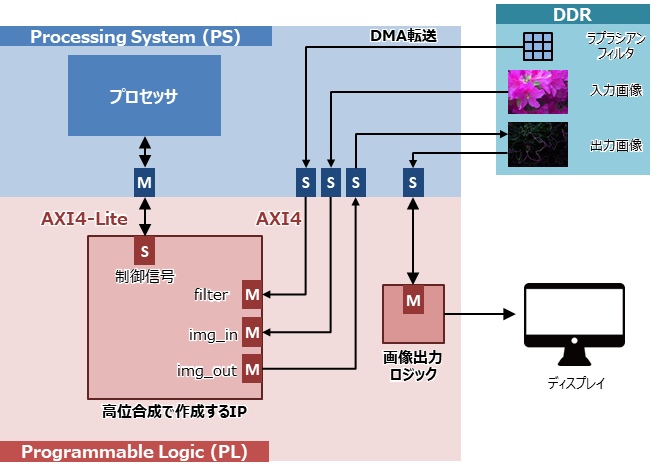
高位合成で作成するFilter2DのIPのイメージ図です。
基本的にプロセッサはDMA転送のアドレスや開始信号などの制御信号を送るだけで、実際の画像や空間フィルタはAXI4マスターインタフェースを介してDMA転送されます。
DDRメモリに保存された入力画像とラプラシアンフィルタをDMA転送でIPに送り、空間フィルタリング処理をIP上で実施します。IPで処理した画像をDDRメモリ上に保存した後、それを静止画出力ロジックからディスプレイに表示しました。
静止画出力ロジックは以下の記事の内容と同じものを使うことにしました。
設定
まず、Configuration Settingから。今回実装対象となるZyboには32ビットのアドレス長のDDR3メモリが搭載されています。

イメージ図に記載した通り、AXI4マスターインタフェース(m-axi)を通じて、画像やフィルタをDDR3メモリとDMA転送するつもりです。
そこで、メモリのアドレス長を超えないように、m_axi_addr64のチェックを外しました。
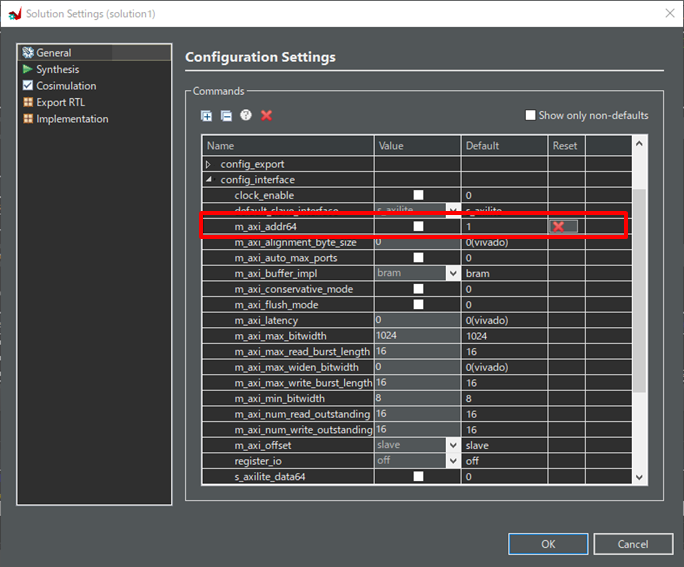
その他の設定は変えていません。
ディレクティブの設定
次に、ディレクティブ(#pragma)の設定について。ディレクティブは高位合成した後のRTLの構成を明示的に指定するための指示子です。
これも基本的にデフォルトのままで変更せずに進めました。デフォルトでは、Filter2D_accelには2種類の指示子が用意されています。
- HLS INTERFACE : IPのポート(関数の引数や戻り値)のプロトコルを設定できる。
- HLS DATAFLOW : 内部関数を並列(パイプライン)処理。今回は、主にArray2xfMatとfilter2DとxfMat2Arrayの3関数が呼び出されており、こういった複数の関数をパイプライン処理させている。
HLS INTERFACE
高位合成の対象となるFilter2D_accel関数には6つの引数と1つの戻り値が存在しています。
void Filter2d_accel(ap_uint<INPUT_PTR_WIDTH>* img_in,
short int* filter,
unsigned char shift,
ap_uint<OUTPUT_PTR_WIDTH>* img_out,
int rows,
int cols)各変数に対しPS部から図のような制御を行うため、表のように、配列を渡すときにはAXI4マスターインターフェースを、値を渡すときにはAXI4-Liteスレーブインタフェースを割り当てています。
| 変数名 | データ型 | デフォルトのインターフェース |
| img_in | 配列を指すポインタ | m-axi |
| filter | 配列を指すポインタ | m-axi |
| img_out | 配列を指すポインタ | m-axi |
| shift | スカラー | s-axilite |
| rows | スカラー | s-axilite |
| cols | スカラー | s-axilite |
| return | スカラー(実際はvoid) | s-axilite |
画像などの大容量の信号はAXI4マスターインターフェースでDMA転送・バーストモードを用いて高速に送信し、制御に必要な信号は転送の頻度が少ないためAXI4-Liteで送るようにしています。
m_axiのdepthは、DDRメモリでのimg_in配列(深さ__XF_DEPTH_IN=14,400)、img_out配列(深さ__XF_DEPTH_OUT=14,400)、filter配列(深さ__XF_DEPTH_FILTER=9)のメモリマップに基づき定めています。
本記事の後半でメモリマップについて解説します。
#pragma HLS INTERFACE m_axi port=img_in offset=slave bundle=gmem0 depth=__XF_DEPTH_IN
#pragma HLS INTERFACE m_axi port=filter offset=slave bundle=gmem1 depth=__XF_DEPTH_FILTER
#pragma HLS INTERFACE m_axi port=img_out offset=slave bundle=gmem2 depth=__XF_DEPTH_OUT実行
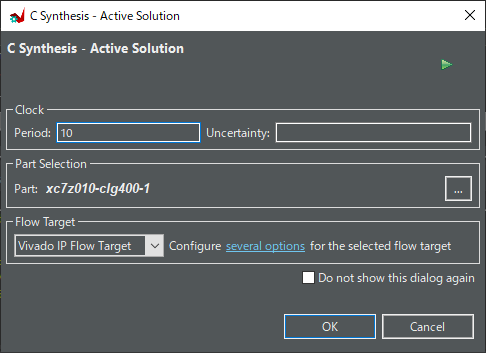
以上の設定が完了したら高位合成をしてみましょう。[C synthesis]を実行します。

クロック周期は10nsとし、ターゲットのチップはZyboに搭載されているxc7z010-clg400-1としました。
結果
高位合成の結果は次の通りです。
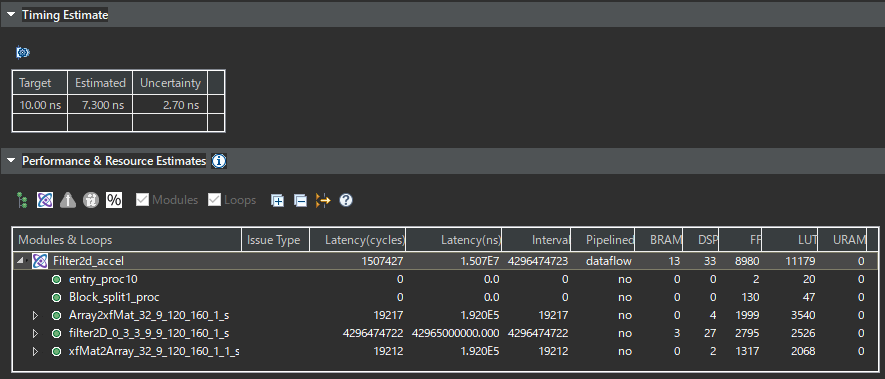
使用リソースは以下の通り。FFに至っては半分くらいのリソースを使っていますが、十分実装可能な範囲です。とはいえ、160×120画素であれば処理可能ですが、より高解像度の画像を扱うには厳しいリソースといえます。
| Filter2D IP | Zynq(xc7z010) | 使用率(%) | |
| FF | 8,980 | 17,600 | 51% |
| LUT | 11,179 | 35,200 | 32% |
| BRAM(36Kbブロック) | 13 | 60 | 22% |
| DSPスライス | 33 | 80 | 41% |
高位合成されたRTL
モジュール構成
合成後のRTLモジュールの構成を調べてみました。細かい構成は省略します(私も追い切れていません)が、最上位モジュールとその一つ下位のモジュール構成を示しました。
最上位モジュールがFilter2d_accelモジュールとなっており、その内部に複数のサブモジュールが配置されています。
- 最上位Filter2D_accel
- 制御信号を送受信するコントロールレジスタ
- control_s_axiモジュール:shift, rows, colsの情報を格納したコントロールレジスタ。画像処理を開始するap_ctrlもここで生成。
- control_r_s_axiモジュール:各配列のポインタ(ベースアドレス)の情報を格納したコントロールレジスタ
- 画像信号をDDRメモリと送受信するためのバッファ
- gmem0モジュール:入力信号を受信するためのバッファ
- gmem1モジュール:空間フィルタを受信するためのバッファ
- gmem2モジュール:出力画像を送信するためのバッファ
- 画像処理モジュール
- Array2xfMatモジュール:配列をMat形式に変換
- filter2Dモジュール:空間フィルタリング実行
- xfMat2Arrayモジュール:Mat形式を配列に変換
- その他のモジュール
- FIFO(First-In-First-Out)
- Block_split1_proc, entry_proc:FIFOに送信するためのプロトコル生成
- 制御信号を送受信するコントロールレジスタ

正直、コントロールレジスタ周辺はかなりややこしい配線になっていますが…、
メインの流れは次の通りです。
- 画像処理を行うための制御情報をAXI4-Liteを通じてコントロールレジスタに書き込む
- 入力画像とラプラシアンフィルタをDDRメモリから読み出す
- 入力画像はgmem0へ
- ラプラシアンフィルタはgmem1へ
- Array2xfMatモジュールで、入力画像をAXI4形式からMat形式に変換する
- filter2Dモジュールで、入力画像とラプラシアンフィルタを受け取り、空間フィルタリング実行。画像処理後の出力画像を出力する
- xfMat2Arrayモジュールで、出力画像をMat形式からAXI4形式に変換する
- gmem2を通じて、出力画像をDDRメモリに書き込む
少し気になっているのは、コントロールレジスタから画像処理するモジュール(例:Array2xfMatなど)にパラメータを送るときに、FIFOを使用する場合とそうでない場合をどう使い分けているかについてです。何か理由があると思うのですが、考察できていません。
例えば、srcPtrとfilterはそれぞれ入力画像とラプラシアンフィルタのDDRメモリ内のベースアドレスですが、この2つはFIFOを介さずに直にコントロールレジスタから読んでいます。一方で、出力画像をDDRメモリに書き込むためのベースアドレスdstPtrはFIFOを通じて送られていました。
配列データのメモリマップ
送受信するimg_inとimg_out、そしてfilterの3つの配列の構成を整理しておきましょう。
xf_custom_convolution_config.hではINPUT_PTR_WIDTH、OUTPUT_PTR_WIDTHともに32ビットとしていました。つまり、img_in配列とimg_out配列は32ビット配列(4byte)となるようにしています。
ap_uint<INPUT_PTR_WIDTH>* img_in;
ap_uint<OUTPUT_PTR_WIDTH>* img_out;
一方、画像1ピクセルのTYPEはXF_8UC3としているので、1ピクセルあたり24ビット(3byte)です。そのため、DDRメモリ内の配列img_inやimg_outは、次のように1ピクセルずつではなく3要素で4ピクセルずつ詰めることになります。
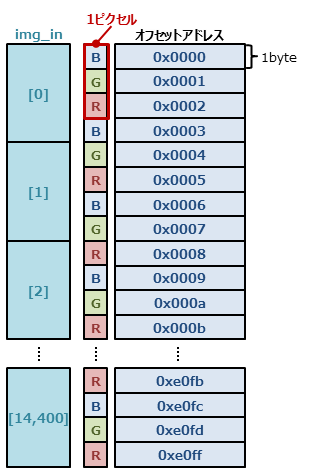
全ピクセル数は160×120ですので、配列の深さ(要素数)__XF_DEPTH_INと__XF_DEPTH_OUTは
$$160\times 120 {\rm [pixel]} \times 3 {\rm [byte/pixel]} / 4 {\rm [byte]} = 14,400$$
となります。
次に、filter配列はshort int型の配列のため、16ビット(2byte)です。
short int* filter;
このビット長では、図のようなメモリ配置になるので、カーネル行列の要素数である9が配列の深さ__XF_DEPTH_FILTERとなります。

配列データの流れ
配列データのバイト数を踏まえて、モジュール内のデータの流れを整理しました。

DDRメモリからは1要素ずつ読み出すので、入力画像は4byteずつArray2xfMatに送られます。
filter2Dは1画素ずつ受信し、画像処理を行うので3byteずつ受け取ります。そのため、Array2xfMatはバイト数によるタイミングの違いを調整しています。
Vitisでアプリケーションを構築するときに、このメモリマップを考慮して、ソースコードを作成しました。配列のサイズやポインタのデータ型、画像データの代入の仕方と関係します。
次回以降の記事で、ソースコードを紹介しようと思います。
まとめ
Filter2D_accel関数を例に、高位合成の方法と結果をまとめました。
次の記事では、協調シミュレーションの結果に基づき、データの送受信のタイミングを整理したいと思います。
最後までご覧いただきありがとうございました!
参考:開発環境
- 開発用PC: Windows 10, 64bit
- Vitis コア開発キット – 2021.2

コメント